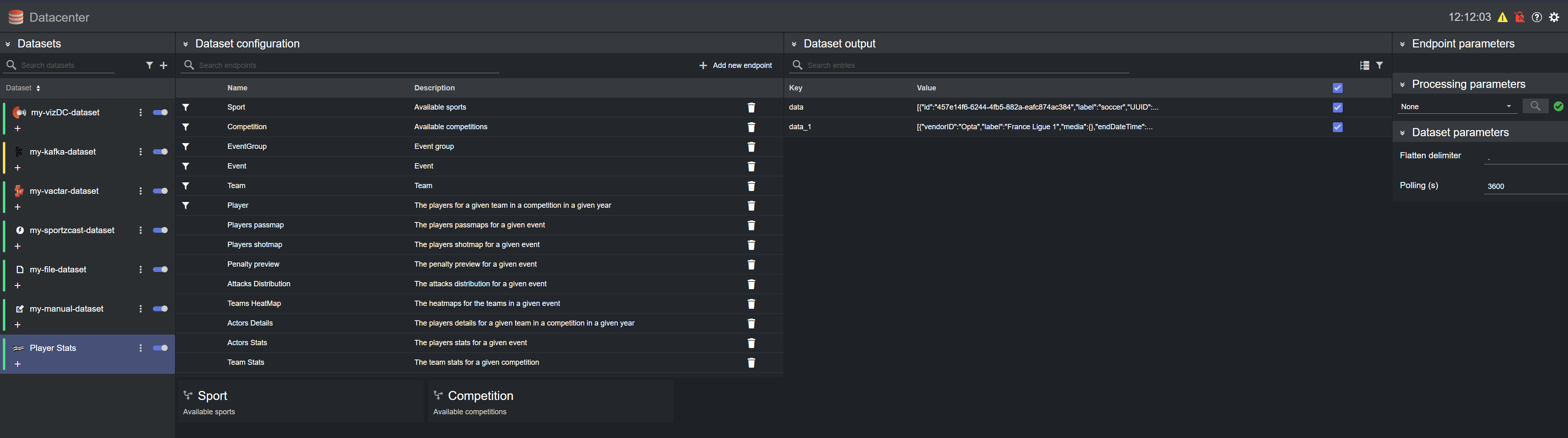
By default, datasets connected to providers providing data in valid JSON format (for example, Fluid Data Services) hold the incoming payload using the key-value pair [data_N][Data_as_JSON_object], where N is the index of the dataset source where the data originates from (for example, in Fluid Data Services, the index of the endpoint configured for the dataset).
In the following scenario, a Fluid Data Services dataset is configured to accept data from two endpoints (Sport and Competition), and subsequently the data is organized in two key-value pairs (data and data_1), one per endpoint:
However, in certain scenarios, all values in the JSON objects need to be associated with a specific key. For these cases, one can automatically flatten the incoming data for a given dataset, by clicking on the flatten icon  in the top-right corner of the Dataset output panel. Doing so results in a flattened version of all the values of the incoming payload, where each atomic value in the JSON object(s) is associated to its own key:
in the top-right corner of the Dataset output panel. Doing so results in a flattened version of all the values of the incoming payload, where each atomic value in the JSON object(s) is associated to its own key:
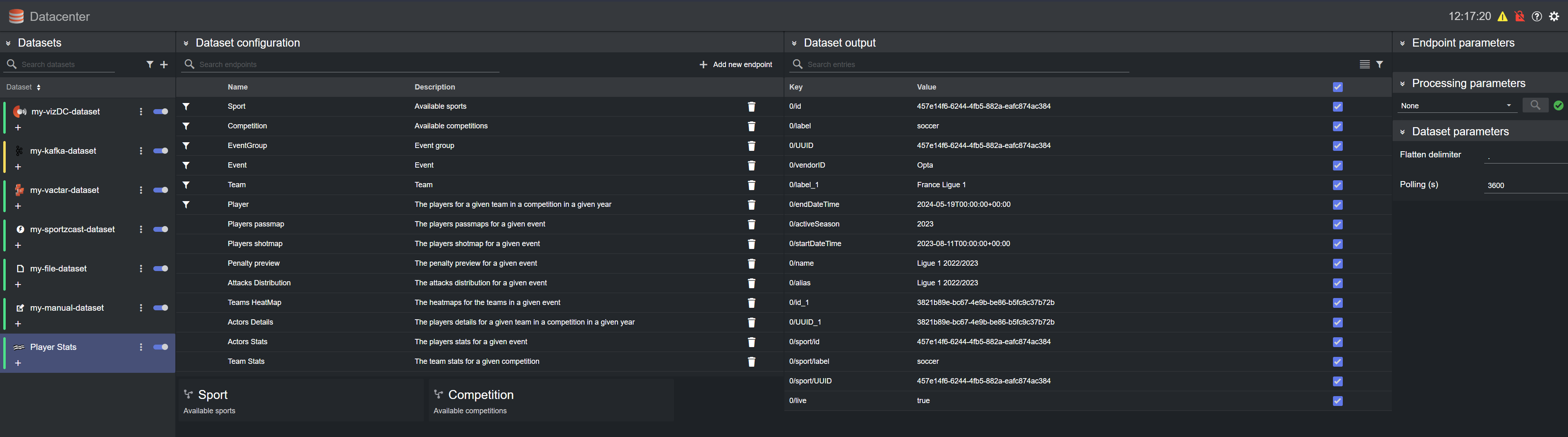
Note: When flattening several objects there is a chance of running into key duplication. Datacenter automatically detects such keys and appends a number to them, to make them unique again (for example, 0/label and 0/label_1 in the image above).
Note: When flattening a payload that contains arrays, the index of the array element is prepended to the the element key, such that unique keys are created (for example, 0/id in the image above).
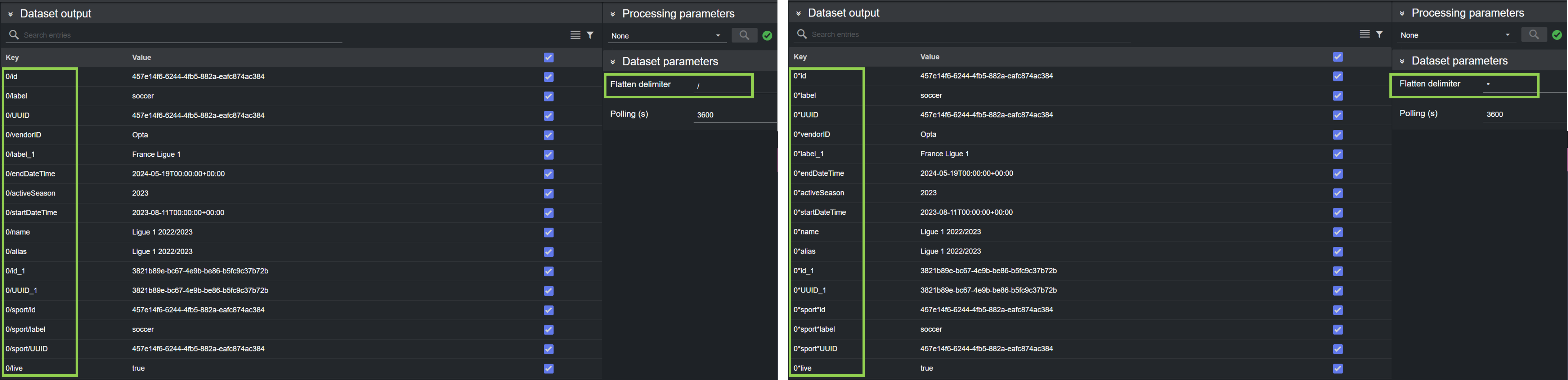
The default separator used to flatten the incoming data is specified in the General configuration in the Admin page. However, the delimiter can be changed per dataset, by using the Flatten delimiter field in the Dataset parameters section of the main view.
To unflatten the data back to the original [data_N][Data_as_JSON_object] format, click on the unflatten icon  in the top-right corner of the Dataset output panel.
in the top-right corner of the Dataset output panel.
Note: The flattening operation is only successful if the data to flatten is in JSON format. If you apply a script prior flattening, make sure the resulting script output is still a valid JSON objects for the flattening to have effect.
Info: For performance reasons, the number of flattened data elements that can be displayed is limited to 1024. This is also true for the search mechanism. All flattened keys are forwarded to the outputs, however.